


Come controllare se una pagina web cambia (shell script)
Dopo un po’ di tempo torniamo a parlare di script e, più nello specifico, di script shell.
Cos’è uno shell script?
Uno shell script è un “programma” che, al suo interno, contiene una serie di istruzioni e/o comandi della shell (riga di comando) tipica dei sistemi UNIX/Linux.
Con le specifiche istruzioni che andiamo a scrivere all’interno dello script, possiamo realizzare procedure (anche molto complesse e articolate) che rispondono alle più svariate esigenze.
Oggi vediamo come creare uno script shell molto comodo, perchè serve ad avvisarci automaticamente con una email quando la pagina di un sito web cambia, senza dover rimanere davanti al pc per delle ore aspettando la modifica e/o “impazzire” con il tasto “F5”. 🙂
Nei portali più evoluti questa funzione viene gestita tramite i feed RSS, ma non è raro imbattersi su alcuni siti web sprovvisti di tale tecnologia.
La domanda, quindi, sorge spontanea:
Come facciamo a sapere quando una pagina web cambia o viene modificata?
Ecco come un semplice script shell può venirci in aiuto.
[adrotate banner=”1″]
Creare uno script shell (bash)
Innanzitutto cominciamo definendo il tipo di interprete:
#!/bin/bash
L’interprete bash è uno degli strumenti, a riga di comando, disponibili ormai nativamente nella maggior parte delle distribuzioni Linux (Debian, CentOS, Redhat, Ubuntu, etc…) e vi si può accedere (tra l’altro) in remoto, previa autenticazione, con un qualsiasi client SSH come ad esempio PuTTy.
Poi andiamo a definire la variabile URL principale cioè la pagina del sito web che vogliamo controllare:
URL="www.nomedominio.xxx"
Successivamente ci dobbiamo collegare alla pagina per salvarne il contenuto in HTML.
A tale scopo ci viene in aiuto l’utility wget:
wget -nc -O "vecchia.html" $URL
Assieme al wget abbiamo inserito -nc che servono ad indicare il download della pagina soltanto alla prima esecuzione dello script.
Con il -O andiamo a specificare invece che la URL deve essere copiata ed inserita in un file dal nome “vecchia.html”.
Infine, abbiamo definito la URL esatta direttamente specificando la variabile $URL.
Successivamente andiamo a riscaricare la pagina:
wget -O "nuova.html" $URL
Questa volta però abbiamo utilizzato l’utility wget solo con il parametro -O che infatti va a scaricare direttamente la pagina in un nuovo file chiamato “nuova.html”.
Poi, anche questa volta, abbiamo utilizzato la variabile $URL per specificare l’indirizzo della pagina web.
A questo punto dobbiamo creare loop (ciclo) che va a confrontare le due pagine “vecchia.html” e “nuova.html” appena scaricate.
Lo facciamo direttamente con l’utility diff, inserendo il tutto in una variabile di nome DIFF:
DIFF=$(diff "vecchia.html" "nuova.html")
l’utility diff controlla le differenze della pagina vecchia.html, nuova.html e va ad inizializzare la variabile DIFF con il risultato ottenuto, che poi riprendiamo successivamente:
if [ "$DIFF" != "" ]
In questo caso inseriamo la condizione dove dichiariamo che, se il valore della variabile $DIFF è diversa da un insieme vuoto (cioè che la pagina web di riferimento è cambiata e/o è stata aggiornata), allora lo script fa una sostituzione, ma vediamo come:
then rm "vecchia.html" mv "nuova.html" "vecchia.html"
cancelliamo la pagina vecchia.html e poi andiamo a rinominare la pagina nuova.html, appena scaricata, in vecchia.html.
In questo caso abbiamo utilizzato dei semplici input da riga di comando come rm e mv.
Così facendo, ogni volta che lo script viene eseguito, se la pagina web è cambiata, la pagina scaricata viene rinominata in vecchia.html e lo script ci notifica eventuali ulteriori modifiche successive alla pagina che stiamo “monitorando”.
Bene: ora che la pagina web ha subito delle variazioni, come facciamo a saperlo automaticamente?
Andiamo semplicemente a notificare il tutto con una email:
echo "La pagina web" $URL "è stata modificata." | mail -s "Controllo aggiornamenti pagina web" indirizzoemail@nomedominio.xxx
utilizziamo quindi una concatenazione grazie all’uso del pipe ( | ), dove dichiariamo il testo nel corpo del messaggio della email con echo ed inseriamo poi l’indirizzo della pagina modificata nel corpo stesso grazie alla solita variabile $URL.
Poi andiamo a creare ed inviare la email con il comando mail.
Con il parametro -s definiamo l’oggetto della email e successivamente il destinatario.
Infine concludiamo lo script:
else echo "La pagina web" $URL "non è stata modificata" fi
con la condizione else, nel caso in cui la variabile $DIFF sia vuota e quindi la pagina web non è stata modificata, andiamo a mostrare un messaggio tramite il comando echo che può essere personalizzato a piacimento.
Infine, concludiamo il ciclo con l’istruzione fi.
Come creare uno script shell per sapere quando un pagina web cambia (clicca per ingrandire)
A seguire proponiamo lo script completo:
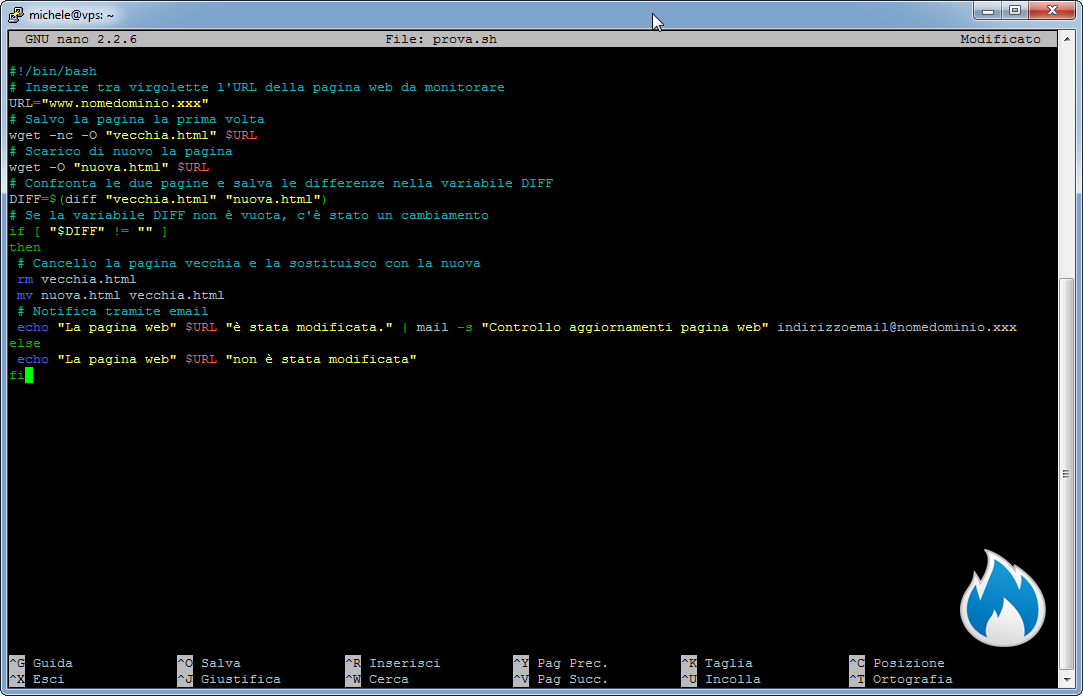
#!/bin/bash # Inserire tra virgolette la URL della pagina web da monitorare URL="www.nomedominio.xxx" # Salvo la pagina la prima volta wget -nc -O "vecchia.html" $URL # Scarico di nuovo la pagina wget -O "nuova.html" $URL # Confronta le due pagine e salva le differenze nella variabile DIFF DIFF=$(diff "vecchia.html" "nuova.html") # Se la variabile DIFF non è vuota, c'è stato un cambiamento if [ "$DIFF" != "" ] then # Cancello la pagina vecchia e la sostituisco con la nuova rm vecchia.html mv nuova.html vecchia.html # Notifica tramite email echo "La pagina web" $URL "è stata modificata." | mail -s "Controllo aggiornamenti pagina web" indirizzoemail@nomedominio.xxx else echo "La pagina web" $URL "non è stata modificata" fi
Lo script che abbiamo visto finora, invia una email ogni qual volta viene apportata una modifica all’interno di una pagina web.
Ma se vogliamo sapere quando cambia un contenuto specifico di una pagina web, come ad esempio solo un numero, come facciamo?
Se state aspettando una nuova versione di un software, potreste avere la necessità di sapere quando viene rilasciata.
Ecco allora che ci viene in aiuto l’utility grep.
Questo comando consente di cercare un qualunque testo (o numero o stringa) all’interno di un file, o nell’output stesso di un comando che abbiamo eseguito nella shell.
A seguire vi proponiamo la stringa, facendo attenzione perché bisogna anche modificare il nome della seconda pagina scaricata:
# Scarico di nuovo la pagina ma la rinomino in porzione.html wget -O "porzione.html" $URL # prendo solo il contenuto che mi interessa grep "numeri o testo" porzione.html > nuova.html
Come potete notare, abbiamo cambiato il nome del file che lo script scarica perché dobbiamo controllarne con grep il contenuto.
Successivamente, grazie all’operatore > sostituiamo il nome in “nuova.html”. In questo modo lo script può continuare senza ulteriori modifiche.
Come creare uno script shell per sapere quando un porzione di una pagina web cambia (clicca per ingrandire)
A seguire lo script completo:
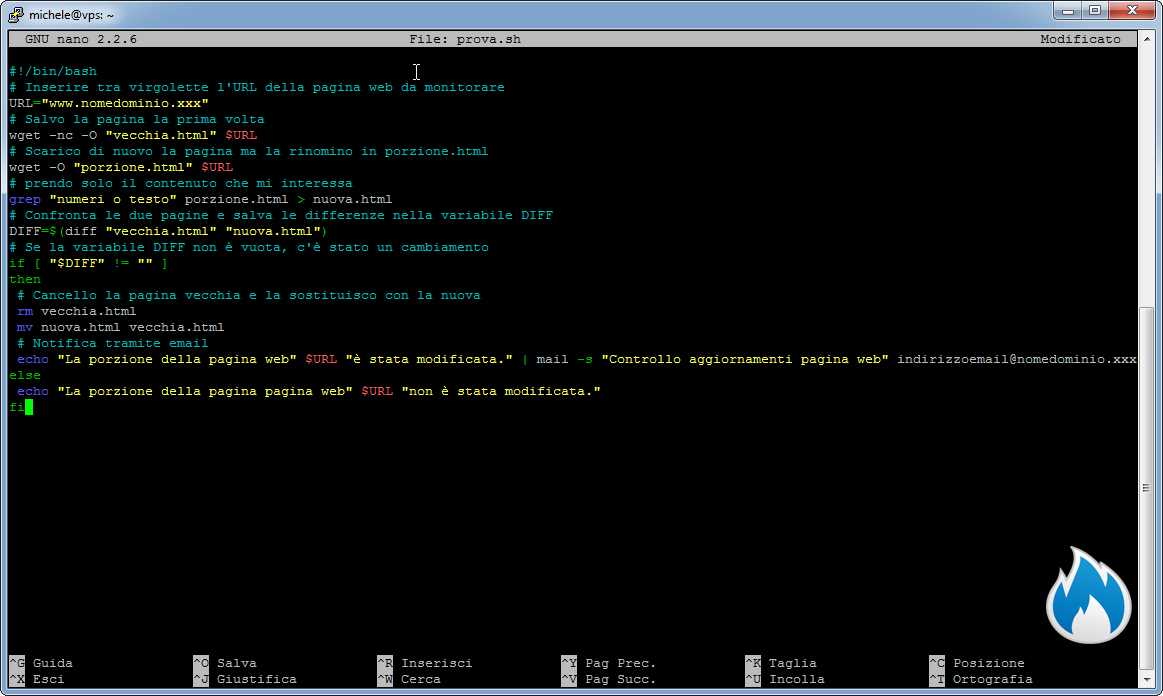
#!/bin/bash # Inserire tra virgolette l'URL della pagina web da monitorare URL="www.nomedominio.xxx" # Salvo la pagina la prima volta wget -nc -O "vecchia.html" $URL # Scarico di nuovo la pagina ma la rinomino in porzione.html wget -O "porzione.html" $URL # prendo solo il contenuto che mi interessa grep "numeri o testo" porzione.html > nuova.html # Confronta le due pagine e salva le differenze nella variabile DIFF DIFF=$(diff "vecchia.html" "nuova.html") # Se la variabile DIFF non è vuota, c'è stato un cambiamento if [ "$DIFF" != "" ] then # Cancello la pagina vecchia e la sostituisco con la nuova rm vecchia.html mv nuova.html vecchia.html # Notifica tramite email echo "La porzione della pagina web" $URL "è stata modificata." | mail -s "Controllo aggiornamenti pagina web" indirizzoemail@nomedominio.xxx else echo "La porzione della pagina pagina web" $URL "non è stata modificata." fi
Esecuzione automatica dello script via crontab
Se siete dei neofiti di script shell in ambiente Linux, dovete sapere che in tali sistemi operativi esiste un demone (chiamato CROND) che consente di pianificare delle attività che, in base alle nostre esigenze, possono essere eseguite in una data e orario precisi, completamente in modo automatico, grazie appunto al crontab.
Come per lo script di backup, che abbiamo visto qualche settimana fa, possiamo utilizzare quasi lo stesso tipo di sintassi, soltanto che al posto di impostare un tempo di 30 minuti, per l’esecuzione dello script, lo impostiamo ad 1 minuto.
Così facendo lo script viene eseguito ogni minuto di ogni ora, per sette giorni la settimana; consentendoci di sapere esattamente quando verrà modificata la nostra pagina web, o porzione della stessa, in base allo script prescelto.
Di seguito un esempio di sintassi da inserire in crontab per l’esecuzione del nostro script:
*/1 * * * * /home/utente/nomedelloscript.sh
Conclusione
Gli script shell sono veramente molto comodi quando dobbiamo fare delle operazioni a volte anche molto complesse e, grazie all’utilizzo di crontab, possiamo creare un connubio che va a risolvere esigenze anche molto particolari.
Ovviamente, parlando nello specifico dello script per vedere se una risorsa sul web cambia, possiamo sempre migliorarlo, aggiungendo altre funzionalità e controlli.
Fateci sapere dunque cosa ne pensate, magari suggerendoci nei commenti anche altre modifiche, così da poter ulteriormente migliorare questa risorsa a beneficio di tutti. 🙂

![Yoast SEO - La Guida Completa [Video 1]](https://magazine.flamenetworks.com/wp-content/uploads/2018/03/Yoast-SEO-La-Guida-Completa-Video-1.jpg)